GDPR: Pseudonimiseren en Anonimiseren – Deel 1
Deze blog laat het verschil zien tussen de methodes van persoonlijk identificeerbare gegevens ten opzichte van direct identificeerbare gegevens en de mogelijke voordelen binnen het kader van de GDPR.
In Artikel 32 uit de Wet bescherming persoonsgegevens wordt aandacht besteed aan Beveiliging van de verwerking en voorgestelde maatregelen: De pseudonimisering en versleuteling van de persoonsgegevens.
Dit is een zeer summiere omschrijving van pseudonimisering. GDPR tracht technologie-onafhankelijk te zijn en het verdient in mijn optiek echt wat meer aandacht dan dit, zeker omdat het een aantal voordelen heeft ten opzichte van volledige direct identificeerbare gegevens.
Zoals voor de meeste wel bekend, gaat GDPR over identificeerbare persoonsgegevens. Volgens Privacy by Design zal er nu bij de meeste toepassingen een applicatie en/of dienst ontworpen worden waar de minimale gegevens worden verzameld voor een specifiek doel.
Voor veel toepassingen zijn direct identificeerbare persoonsgegevens nodig. Een bank account waarbij de gegevens zijn geanonimiseerd is niet echt bruikbaar als u aan de telefoon zit met een vraag over uw account.
Als het enigszins mogelijk is, zou ik u willen adviseren om wel de weg in te slaan die leidt tot anonimiseren. Dit kan in stappen via pseudonimisering naar anonimiseren, waarbij het risico van een datalek op ernstige gevolgen voor de betrokkene(n) steeds lager wordt. Bij volledig anonieme gegevens is het risico zelfs nul.
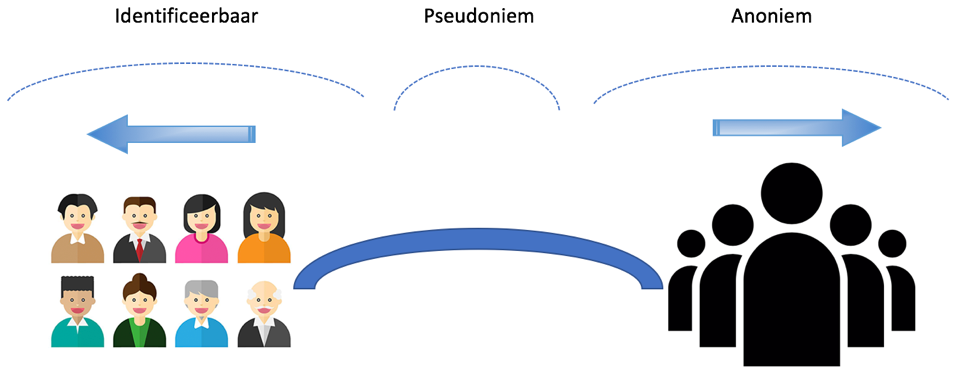
Definities
De definitie aldus Wikipedia (2017): Pseudonimiseren is een procedure waarmee identificerende gegevens met een bepaald algoritme worden vervangen door versleutelde gegevens (het pseudoniem). Het algoritme kan voor een persoon altijd hetzelfde pseudoniem bepalen, waardoor informatie over de persoon, ook uit verschillende bronnen, kan worden gecombineerd.
Pseudonimiseren kan dus gezien worden als een beveiligingsmaatregel. Het vermindert het privacy risico van de betrokkenen en het bewerkingsrisico voor de organisatie(s).
*Nog even voor de duidelijkheid: De GDPR stelt pseudonimiseren van gegevens gelijk aan direct identificeerbare persoonsgegevens.
Anonimiseren betekent: Verwisseling van persoonsgegevens in gegevens die niet langer gebruikt kunnen worden om een natuurlijk persoon te identificeren, daarbij in ogenschouw nemende ‘alle middelen die hiervoor redelijkerwijs gebruikt kunnen worden’ door zowel een verantwoordelijke als een derde partij.
Een belangrijke factor hierbij is dat de verwerking onomkeerbaar moet zijn. (Wikipedia, 2017)
Pseudonimisering is omkeerbaar
Anonimiseren is onomkeerbaar
Waarde anonieme gegevens
Je kan je afvragen of anonieme gegevens nog wel waarde hebben; een organisatie kan anonimiseren inzetten wanneer een organisatie de gegevens nog wel wil bewaren voor analytische of statistische doeleinden, maar herleiden tot individuen niet langer noodzakelijk of rechtmatig is.
Ook in een applicatie straat, zoals bijvoorbeeld in de bekende OTAP -straat, is inzet van anonieme gegevens waardevol. Een O, T en zelfs A-omgeving zou namelijk alleen gebruik moeten maken van anonieme gegevens.
Maar dit is niet eenvoudig. De Article 29 Working Party (het adviesorgaan van vertegenwoordigers van alle Europese Autoriteiten Persoonsgegevens) stelt dan ook dat anonimiseringstechnieken privacy waarborgen leveren, mits de toepassing van dergelijke technieken volledig zijn ontwikkeld en uitgevoerd.
Een voorbeeld van pseudonimisering:
Stel u heeft persoonsgegevens verzameld van een klant genaamd Jan Jansen. In de meest eenvoudige vorm van pseudonimisering worden de direct identificeerbare gegevens veranderd in niet direct identificeerbare gegevens;
Jan Jansen wordt ds11111. De gegevens worden versleuteld opgeslagen.
De versleuteling is een extra maatregel, de gegevens bewerker is nog steeds in staat om de betrokkene te identificeren door de vertaaltabel of omzet algoritme te gebruiken om ds11111 naar Jan Jansen om te zetten.
Pseudonimisering is daardoor omkeerbaar en de GDPR ziet deze dus nog steeds als persoonsgegevens met de bijbehorende maatregelen.
Pseudonimisering vermindert wel de kans op misbruik van de gegevens bij een eventueel datalek, want je moet weten hoe het algoritme werkt of toegang krijgen tot de vertaaltabel.
Waarbij pseudonimisering wel veel aandacht aan gegeven moet worden, is de mogelijkheid om uit verschillende bronnen de gegevens weer te kunnen herleiden. Een uitwisseling van de omzet tabel over de bronnen moet worden voorkomen.
Wordt vervolgd
Maar hoe zit het nu precies met anonimiseren? En wat zijn nu de voordelen van pseudonimiseren of anonimiseren van de persoonlijke gegevens? In deel 2 kunt u hier alles over lezen.
Ook zal ik dan een aantal anonimiseer methodes behandelen en een korte beschrijving geven van de aanpak.
