GDPR: Pseudonimiseren en Anonimiseren – Deel 2
Vorige week hebben we in deel 1 de termen pseudonimiseren en anonimiseren belicht. We hebben daarbij gekeken naar de exacte definities en ook voorbeelden aangehaald van pseudonimiseren. Een belangrijke conclusie die we kunnen trekken uit de blog van vorige week is dat pseudonimisering omkeerbaar is, en anonimisering onomkeerbaar.
In deze blog zullen we verder ingaan op anonimiseer methodes.
GDPR Voordelen
Onderstaande tabel geeft inzicht in de maatregelen van de leesbaarheid van de gegevens.
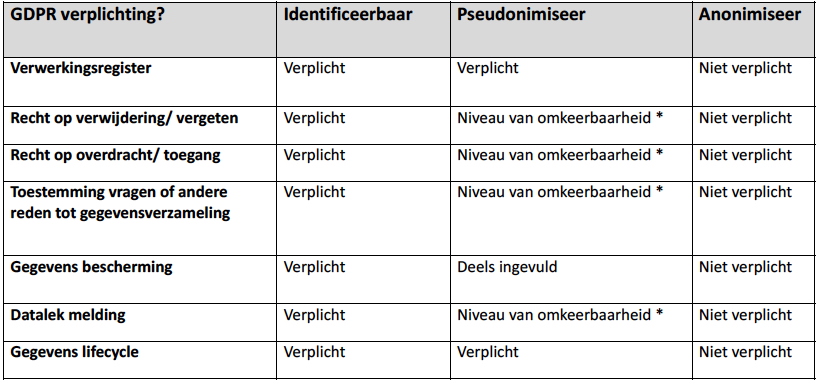
Voorbeeld
Om bovenstaande tabel iets te verduidelijken, bespreek ik graag het voorbeeld van een melding van een datalek. Hoe en wanneer wordt dit gemeld?
Er wordt melding gemaakt bij de autoriteit persoonsgegevens en/of betrokkene(n) als er persoonlijke identificeerbare gegevens zijn vrijgekomen.
De autoriteit van persoonsgegevens moet hierbij worden geïnformeerd als het datalek leidt tot ernstige nadelige gevolgen voor de bescherming van persoonsgegevens.
De betrokkene(n) moeten worden geïnformeerd wanneer er een hoog risico bestaat op ernstige nadelige gevolgen voor de bescherming van persoonsgegevens.
Bij een datalek is er dus zeker winst te behalen met een sterke pseudonimisering of nog beter door middel van anonimisering.
Als er voldaan wordt aan bepaalde voorwaarden (*) van pseudonimisering, is het risico voor de betrokkene(n) lager en zou de meldplicht ook minder zwaar ingezet hoeven te worden.
* Als uit te sluiten is dat de vertaaltabel die gebruikt is bij pseudonimisering van de persoonsgegevens te verkrijgen is (door deze vertaaltabel bijvoorbeeld niet op dezelfde systemen te plaatsen, of deze vertaaltabel door meervoudige encryptie onleesbaar te maken) dan kan in bepaalde gevallen (na overleg met de Autoriteit Persoonsgegevens) de gegevens worden gezien als anonieme gegevens.
Om bovenstaande te ondersteunen, wil ik je graag even het Artikel 12(2) van de GDPR laten lezen:
De verwerkingsverantwoordelijke faciliteert de uitoefening van de rechten van de betrokkene uit hoofde van de artikelen 15 tot en met 22. In de in artikel 11, lid 2, bedoelde gevallen mag de verwerkingsverantwoordelijke niet weigeren gevolg te geven aan het verzoek van de betrokkene(n) om diens rechten uit hoofde van de artikelen 15 tot en met 22 uit te oefenen, tenzij de verwerkingsverantwoordelijke aantoont dat hij niet in staat is de betrokkene te identificeren.
Anonimiseer methodes
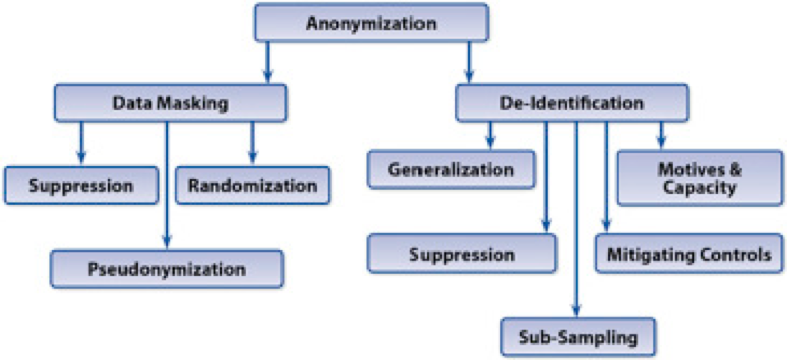
In bovenstaande afbeelding is goed het verschil te zien wat het eindproduct van anonimisering is. Bij gegevens-maskeren is er nog steeds sprake van een algoritme. Het is een omkeerbare techniek en zal dus resulteren in ge-pseudonimiseerde gegevens. Met een randomizer engine is de kans daarop al veel minder.
Om echt anonieme gegevens te krijgen moet er eerst iedere direct identificeerbare gegevens uit de gegevens gehaald worden, en dan verder verrijkt of gestript worden door diverse technieken. Er zijn op de markt verschillende tools beschikbaar voor ‘de-identification’ van gegevens.
Aanpak
Gezien het belang dat ermee gepaard gaat voor de betrokkenen, kan er niet lichtzinnig over anonimiseren gedacht worden. Een goede aanpak is een cyclus proces van risico afweging – zwaarte – meten en weer de cyclus in voor eventuele bijstelling.
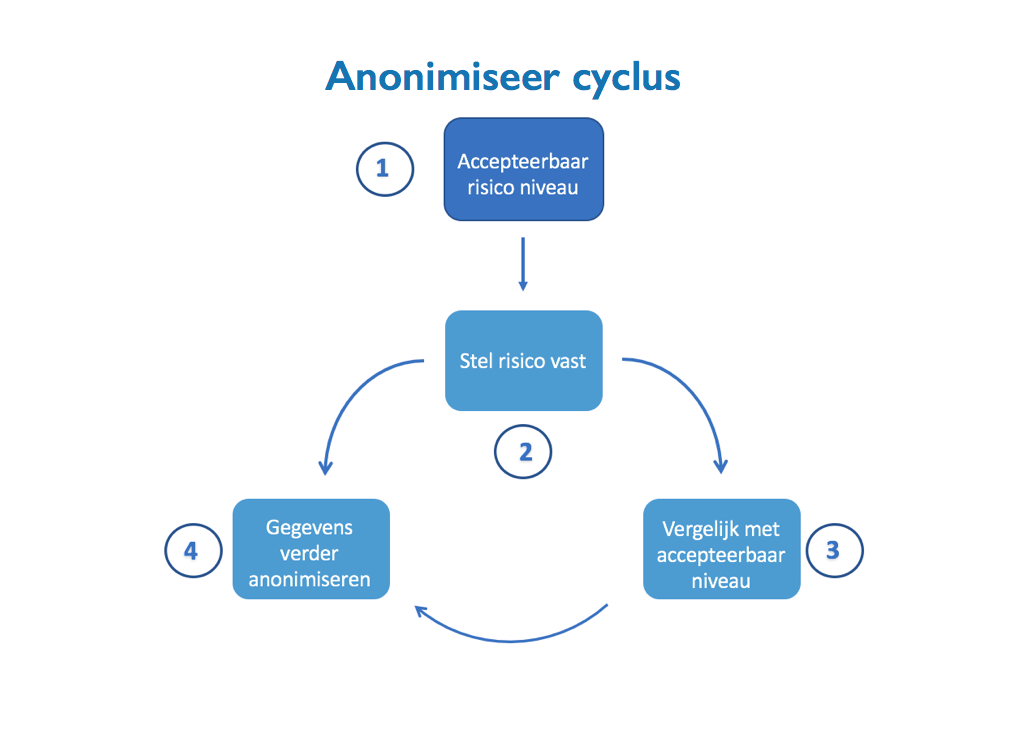
1: Stel accepteerbaar risiconiveau vast
Gebaseerd op de karakteristieken van de gegevens en historische ervaringen wordt een accepteerbaar risico vastgesteld. Nb. In De GDPR betekent dat het NIET te herleiden mag zijn naar identificeerbare persoonsgegevens.
2: Stel risico vast
De geanonimiseerde gegevens worden nu vergeleken met de originele gegevens om vast te stellen of er een re-identificeerbaar risico bestaat. Kortom, zou het mogelijk zijn de originele gegevens te herleiden?
Dit is lastig, er zal een meet methode moeten worden gemaakt of zelfs reverse engineering van de gegevens nodig zijn om zwakke plekken te vinden in de anonimiseer slag. Er zijn tools in de markt (de-identification tooling) om daarbij te helpen.
3: Vergelijk met accepteerbaar niveau
Neem de uitkomst van fase 2 en zet deze af tegen het vastgestelde accepteerbare niveau uit fase 1.
4: Gegevens verder anonimiseren
Wanneer de uitkomst van fase 3 niet acceptabel is, dus onder het niveau van 1 zit, dan zullen additionele anonimiseer slagen nodig zijn om het risico te verminderen.
Dit zal weer de input zijn voor de cyclus beginnend bij fase 2.
Ik hoop dat je nu een goed beeld hebt gekregen van de voordelen en nadelen van pseudonimisering en anonimisering en dat je ook zelf aan de slag kunt met de anonimiseer methodes.
Wil je meer weten over anonimiseren? Dan raad ik je aan om het boek “The Complete Book of Data Anonymization: From Planning to Implementation” van Balaji Raghunathan te lezen.
